
In theory object storage gives us the perfect landing tier for backup data. The platforms effectively scale infinitely and we can replace nodes as they come out of warranty easy - so worrying about total capacity or data management is less of a thing.
But, there are some cases where you may want to be able to move between object storage providers, in our case we simply wanted to move the Veeam Backup for Microsoft 365 data to a different region so I wanted to see what was possible and how we might go about it.
We run on-premise Cloudian clusters, but this will work pretty much any.. object storage you are using with Veeam Backup for M365 today.
Disclaimer! ⚠️ This is, as at writing an unsupported method for migrating this data between buckets/object stores.
Can't you just use Move-VBOEntityData?
So, Veeam have a tool for this, called Move-VBOEntityData, but.. per the documentation.
Data move from object storage to another object storage (including object storage specified as target for backup copy jobs) or a local repository is not supported.
It would have been nice though right? We could then spin up a new object-backed repository and simply migrate the data across and point the job at it once complete.
So, we need to look to another solution.
The Process
After MUCH trial and error, many demo tenancies and repositories. I think I may have cracked the code.
I have scripted this end to end and mine differs slightly from the snippets below but you can combine these and sprinkle in your requirements.
Step 1 - Bucket Creation
Create buckets on your destination object cluster that you require for your migration and get access credentials.
I have left this code out but I use the Cloudian Admin API to create a tenant and then generate credentials and then generate the buckets.
Step 2 - Validate/Add Credentials and Object Storage
You could do this manually using the GUI but this is how you can validate and add the required destinations.
$s3DestinationEndpoint = Read-Host "Enter S3 endpoint desintation, i.e s3.yourplace.com"
Now we will validate if the access key exists, if so move on, otherwise ask for the secret and then add it.
$s3AccessKey = Read-Host "Enter access key for destination"
$s3CompatibleAccount = Get-VBOAmazonS3CompatibleAccount -AccessKey $s3AccessKey
if ($null -eq $s3CompatibleAccount)
{
Write-Host "Credentials do not exist, we need to create an account in Veeam M365."
$s3SecurePassword = Read-Host "Enter secret key for $s3AccessKey" -AsSecureString
$s3AccountDescription = Read-Host "Enter credential description, i.e tenant-name-here"
Add-VBOAmazonS3CompatibleAccount -AccessKey $s3AccessKey -SecurityKey $s3SecurePassword -Description $s3AccountDescription
#get account again
$s3CompatibleAccount = Get-VBOAmazonS3CompatibleAccount -AccessKey $s3AccessKey
}
Right, now you have validated and or added the new credential, we can validate if it works..
Write-Host "Connecting to $s3DestinationEndpoint....."
$s3DestinationConnection = New-VBOAmazonS3CompatibleConnectionSettings -Account $s3CompatibleAccount -ServicePoint $s3DestinationEndpoint
All going to plan, that will have worked. Now we need to validate if the target buckets exist over on the object storage destination.
You can feed these in via a param or if you want it to be a bit interactive use the following while loop to keep adding names to the array until an empty line.
## now validate destination buckets exist and folders exist for this account.
Write-Host "Enter 1 or more TARGET bucket (and repository names)..... "
Write-Host "when finished, enter a BLANK line to exit loop"
$bucketAndRepositoryNames = @()
do {
$input = (Read-Host "Enter name, i.e tenant1-onedrive, tenant1-sharepoint... etc")
if ($input -ne '') {$bucketAndRepositoryNames += $input}
}
until ($input -eq '')
Write-Host "We got the following."
$bucketAndRepositoryNames
Now comes the part where we will start adding these buckets in so that we can eventually add a repository that is backed by object storage for the Microsoft365 backup jobs to be repointed to after the migration.
The below loops through your input above and does the following
- Checks if bucket exists
- Checks if target folder exists, if not creates it
- Checks for an S3 compatible storage repository with the name exists, if not creates it
foreach ($targetBucket in $bucketAndRepositoryNames)
{
$s3DestinationBucketName = $targetBucket
$s3DestinationBucket = Get-VBOAmazonS3Bucket -AmazonS3CompatibleConnectionSettings $s3DestinationConnection -Name $s3DestinationBucketName
if ($null -eq $s3DestinationBucket)
{
Write-Host "Destination bucket $s3DestinationBucketName was not found for this account... verify and re-run"
exit
}
$folderName = "M365Backups" ## you can name this whatever you require.
$s3DestinationFolder = Get-VBOAmazonS3Folder -Bucket $s3DestinationBucket -Name $folderName
if ($null -eq $s3DestinationFolder)
{
Write-Host "Destination folder VBOData was not found in $s3DestinationBucketName ... we will add it"
Add-VBOAmazonS3Folder -Bucket $s3DestinationBucket -Name $folderName
$s3DestinationFolder = Get-VBOAmazonS3Folder -Bucket $s3DestinationBucket -Name $folderName
}
#use the same name as the bucket name
$vboS3CompatibleRepositoryName = $s3DestinationBucketName
$vboDestinationS3Compatible = Get-VBOObjectStorageRepository -Name $vboS3CompatibleRepositoryName
if ($null -eq $vboDestinationS3Compatible)
{
Write-Host "s3 Object repository $vboS3CompatibleRepositoryName doesnt exist, we will add it"
Add-VBOAmazonS3CompatibleObjectStorageRepository -Folder $s3DestinationFolder -Name $vboS3CompatibleRepositoryName -Description "Automatically added by script"
#fetch it
#$vboDestinationS3Compatible = Get-VBOObjectStorageRepository -Name $vboS3CompatibleRepositoryName
}
else {
Write-Host "Object repository exists, no need to add"
}
}
That's step 1 complete, we have now got to a point where the object storage has been validated or added into the VBM server, ready for us to migrate data and eventually swing the data around and reassign some jobs.
Step 3 - Data Migration
This is actually manual at the moment but could be easily automated. So just use whatever tool to migrate the data.
There are plenty of options out there just bear in mind unless you plan on making your source buckets publicly readable/listable (hint.. do not..) then you can't use the typical aws s3 cli or derivatives as they only support connecting to a single tenancy storage account and in our case we are going inter-region, but this may well be for some people between providers.
Make sure you use a proper s3 tool to do this, not just download the data and re-upload it.
Importantly, VALIDATE the object counts and data size on each side match before moving on.
Step 4 - Add repository, delete old repository, move jobs
With the destination now validated and the data moved it is crunch time.
For reference, my example here assumes the names for the following all match
- Object storage name
- Repository name
- Job name
Example destination: tenant1-exchange-location2
Example source: tenant1-exchange-location1
You will note we ask for a source/destination location code, the script below uses these (since we are cloning the existing repository) to then rename it, in the example above the tenant1-exchange-location1 settings will be cloned into a new repository called tenant1-exchange-location2
The process my script follows is
- Ask for organisation
- Grab all jobs for organisation
- Disable the jobs
- Generate details for new repository, using the same settings from our source (retention levels etc), also does the location naming switch, and places the repository back on the existing proxy
- Assigns job temporarily to "Default Backup Repository"
- Deletes the existing repository from Veeam (i.e tenant1-exchange-location1) this is to remove the lock, if you don't do this then the new repo will not add
- Adds new object back repository with the same settings but at the destination and the name, i.e tenant1-exchange-location2
- Assigns the job to this new repository
$organisationName = Read-Host "Please enter full organisation name (incl .onms...)"
$sourceReplace = Read-Host "Enter SOURCE location code, i.e location1"
$targetReplace = Read-Host "Enter DESTINATION location code, i.e location2"
$vboOrg = Get-VBOOrganization -name $organisationName
$tempRepo = Get-VBORepository -Name "Default Backup Repository"
if ($null -eq $vboOrg)
{
Write-Host "VBO organisation not found"
exit
}
Write-Host "Found $vboOrg"
Write-Host ""
# you could add a select here, or allow for manual entry in the name and or use that loop code above for multiple..
$vboJobs = Get-VBOJob -Organization $vboOrg
$vboJobs | Disable-VBOJob
Write-Host "Jobs have been disabled"
foreach ($job in $vboJobs)
{
Write-Host "Processing $($job.Name)"
$repo = Get-VBORepository -Name $job.Repository.Name
#move to temp repository so we can delete the existing
Set-VBOJob -Job $job -Repository $tempRepo
#generate details for new repo, find the path/proxy and do name replace
$newRepoName = $repo.Name.Replace($sourceReplace, $targetReplace)
$pathSplit = $repo.Path.Split('\')
$newPath = "$($pathSplit[0])\$($pathSplit[1])\$newRepoName"
Write-Host "Using location for new repository " + $newPath
#get the object repo, remember this assumes it's the same name all the way through (job/repo/object)
$objectRepo = Get-VBOObjectStorageRepository -Name $newRepoName
Write-Host "Using this object repository " + $objectRepo.Name
Write-Host "Removing the following repository from VBO " + $repo.Name
#remove old before adding new otherwise it will error it's in use.
Remove-VBORepository -Repository $repo
Write-Host "Adding a new object-backed repository " + $newRepoName
#you may need to change this based on your repository setup.
Add-VBORepository -Proxy $repo.Proxy -Name $($newRepoName) -RetentionType $repo.RetentionType -RetentionPeriod $repo.RetentionPeriod -RetentionFrequencyType $repo.RetentionFrequencyType -DailyTime $repo.DailyTime -DailyType $repo.DailyType -ObjectStorageRepository $objectRepo -Path $newPath
#fetch the new repository
$newRepo = Get-VBORepository -Name $newRepoName
#assing the job back from a temporary repo to the newly added repo
Set-VBOJob -Job $job -Repository $newRepo
Write-Host "Assigning job to " + $newRepoName
Write-Host "Job complete."
Write-Host ""
}
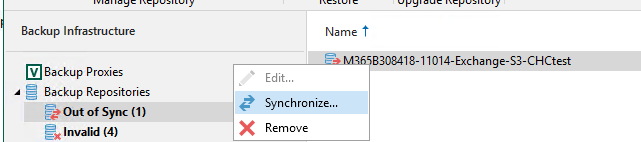
Step 5 - Check backup repository health
Check if any backup repos are out of sync (hint, they will be), sync them up using the UI, right click each and syncronize. This will take a minute or so.
6. Run / re-enable jobs
This is where it get's fun and is the moment of truth. Here is my take on it so far, still got a few more demo tenants to process but.
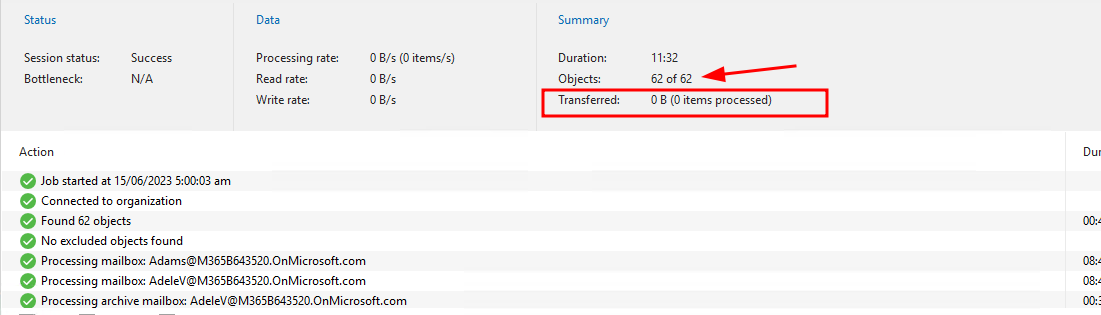
Exchange
This flew through and validated very quickly, no data was transferred and it successfully picked up where it left off.
Here is the first run
Sharepoint-based
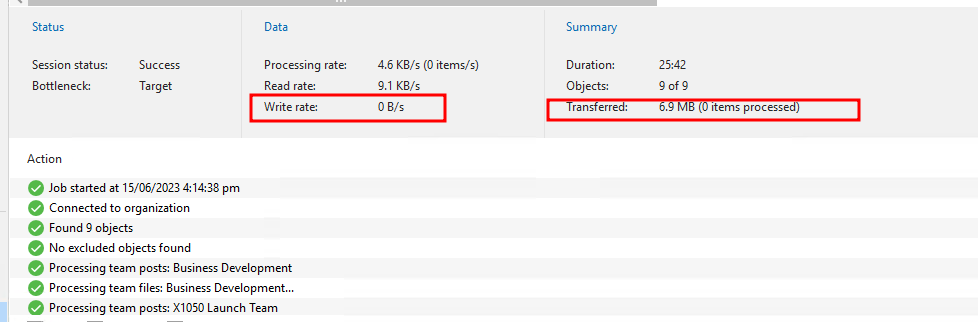
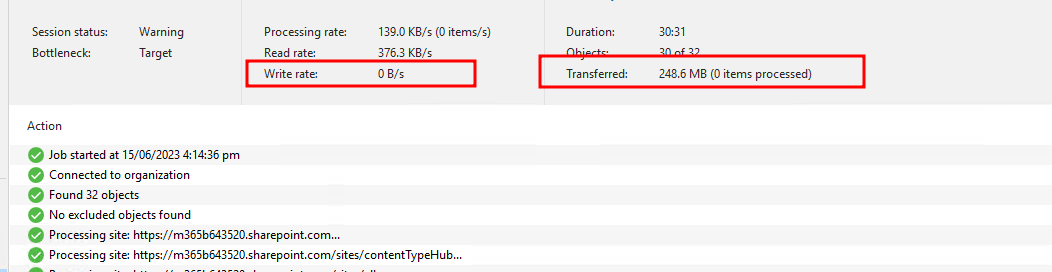
Now anything that is Sharepoint based, effectively everything else took much longer due to throttling. To me it looks as if we had to read out everything, or at least a lot that was online again to validate that everything was there.
Seemed to feel like it was about the same amount of time as when you first onboard the customer, depending on volumes it may be a few hours to days to complete. I haven't tested this on a large demo tenancy yet. The next run though goes through as expected, incremental job which completes in a usual timeline.
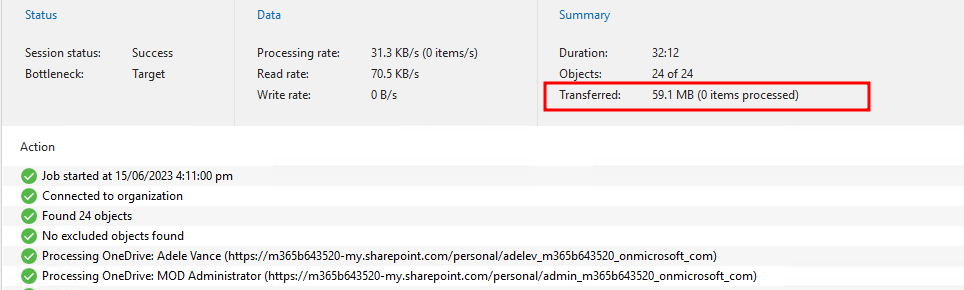
For reference here were the first job runs of each for this tiny tenancy, you can see a transfer by no items processed and no write rate to the migrated repository.
Teams
Sharepoint
OneDrive
What about restoring?
This was of course part of the testing and it works as expected, you can open up any of the explorers and browse, view, restore data.
Exchange
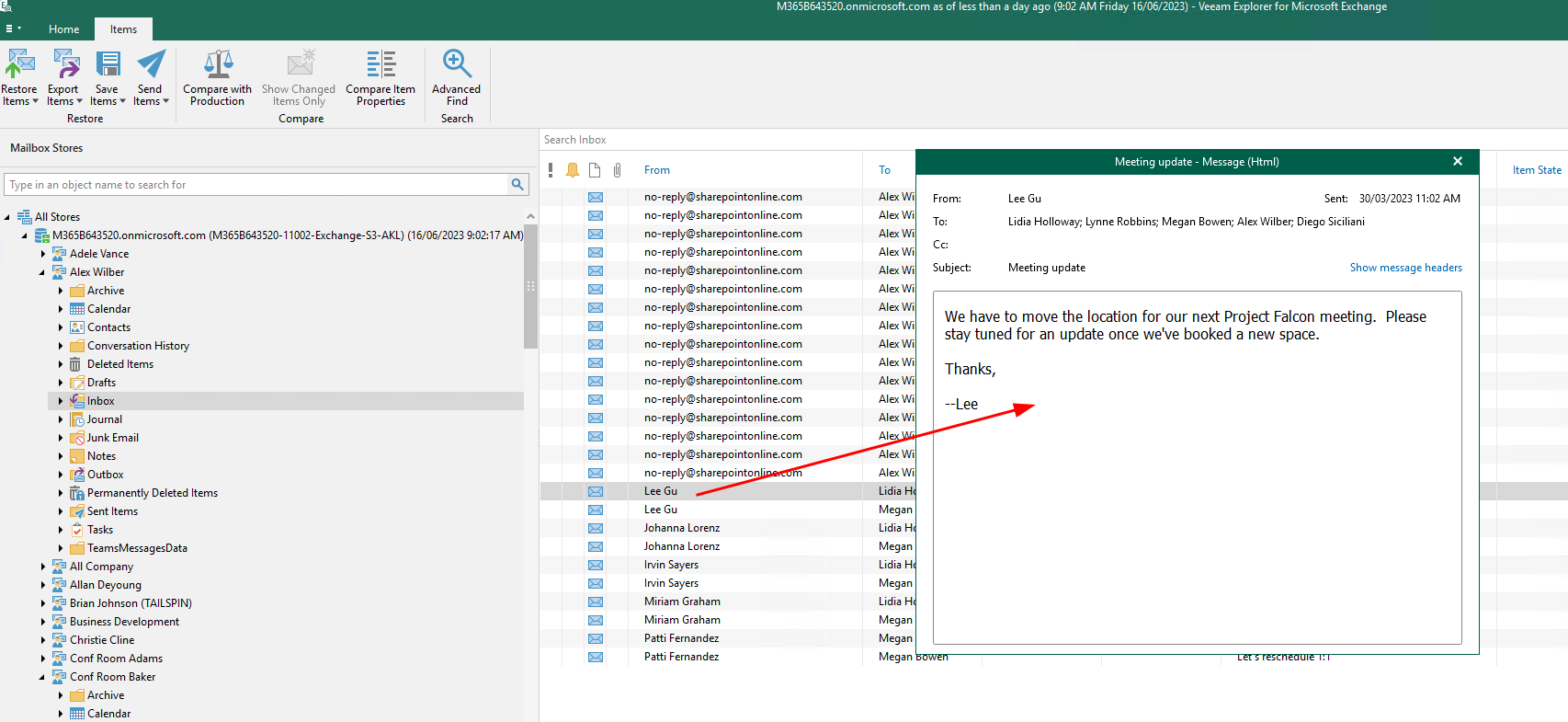
Teams
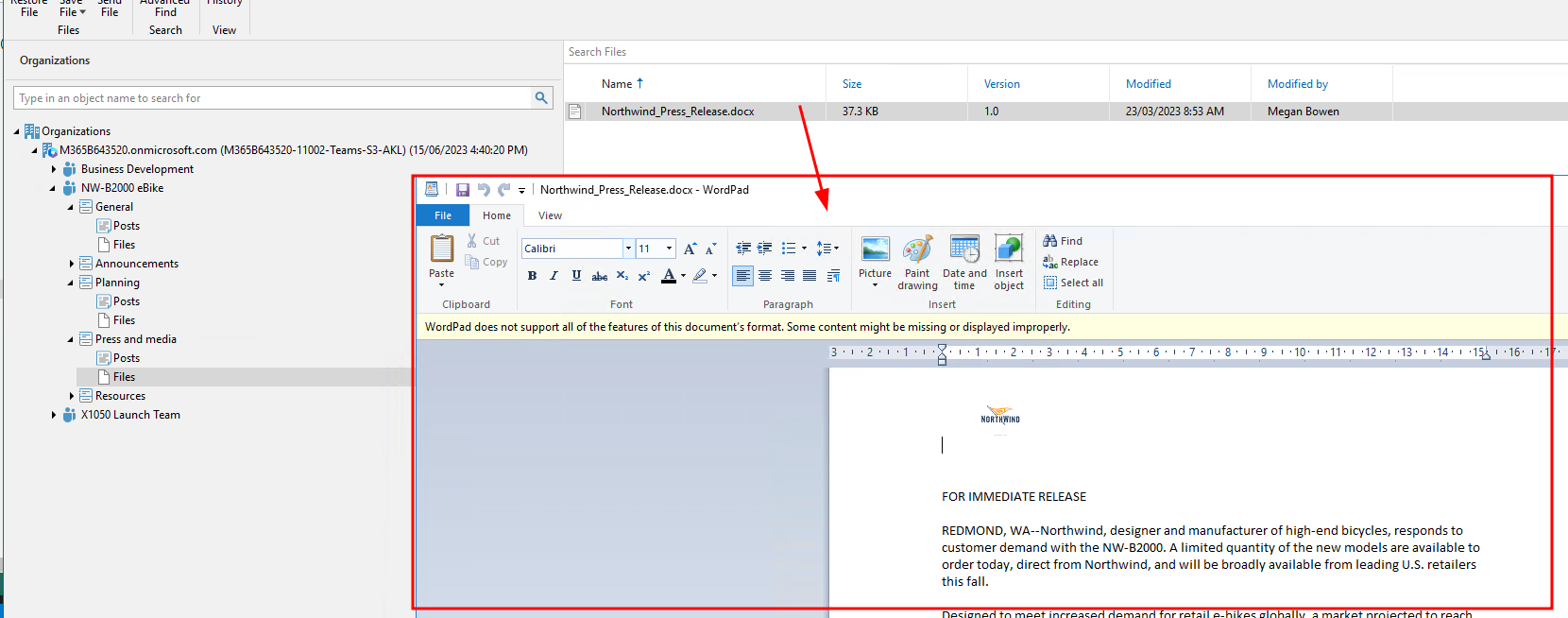
Sharepoint
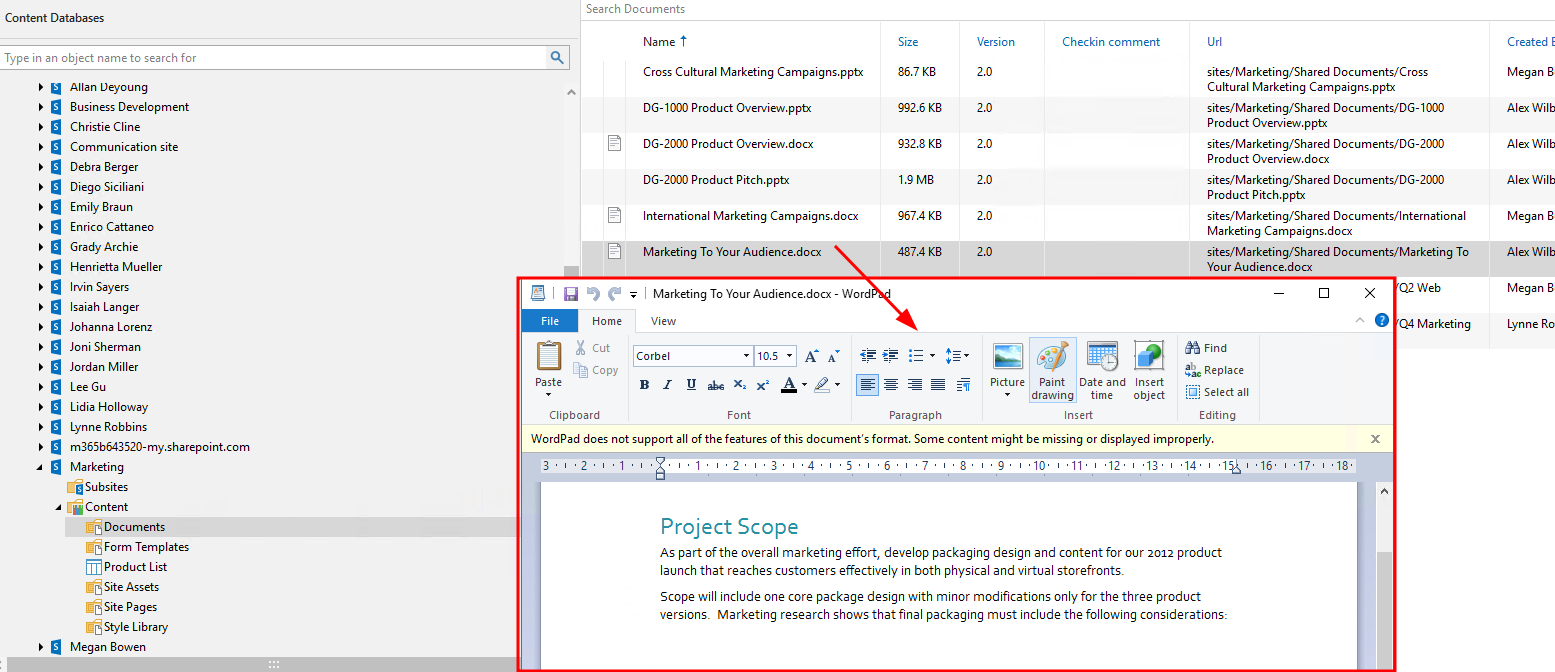
OneDrive
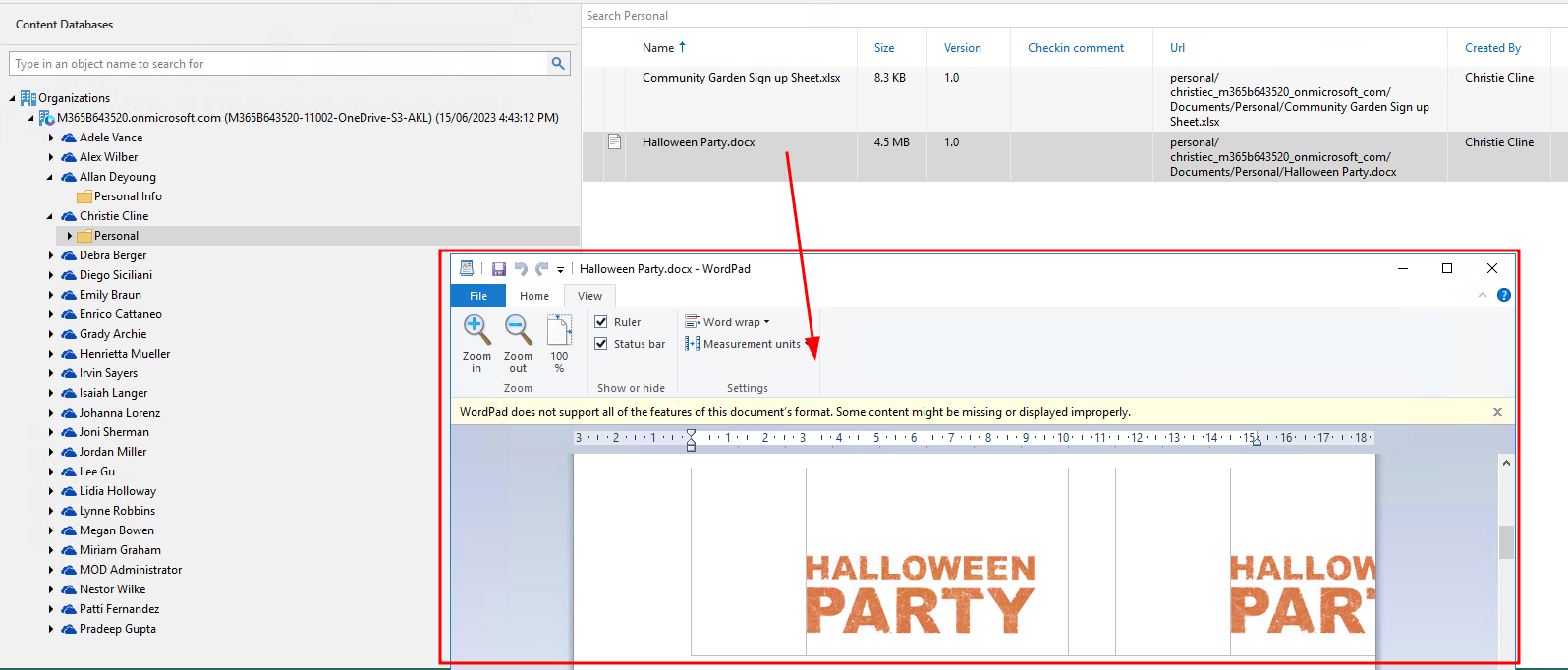
Great! There you have it, a migration from one cluster to another - as I mentioned this could be used for migration from say Azure to Wasabi, AWS to On-premise etc
But REMEMBER.. ⚠️
⚠️ This is, as at writing an unsupported method for migrating this data between buckets/object stores.
Any questions? Hit me up on Twitter @benyoungnz
Thanks for reading my deep dive.

