

Securely unlocking decades-old health data for medical research

Clean rooms are a trending topic right now. During Ignite 2024 Microsoft announced a technical preview of Azure Confidential Clean Rooms. This caught my eye and got me thinking that this could be a great use case to unlock data locked away in backup sets, enabling data-reuse whilst maintaining privacy and security of that data throughout the process.
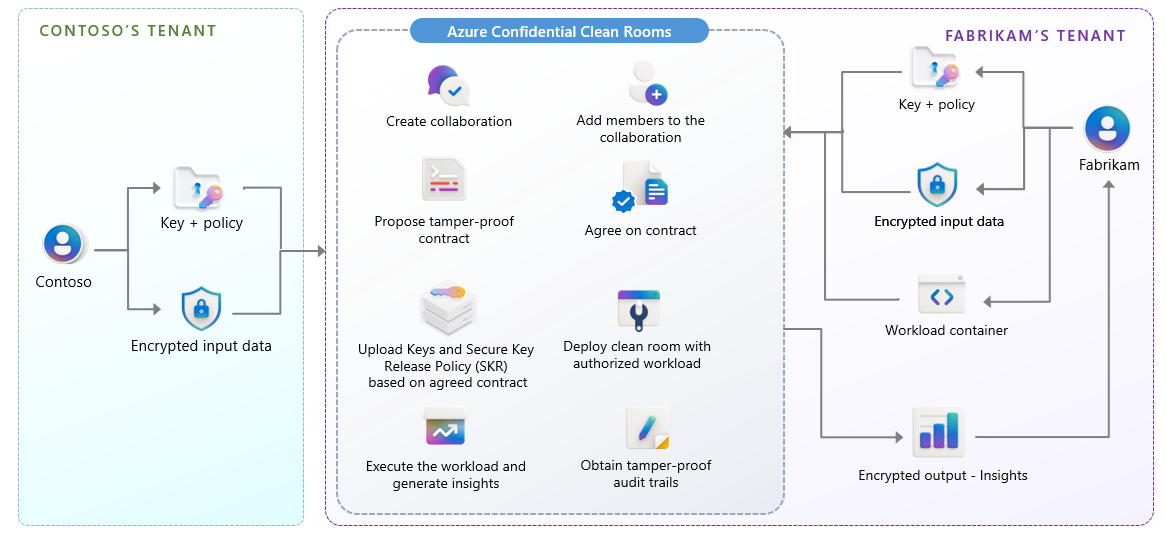
Before we look at a scenario, you can see below from the Microsoft architecture how the Clean Room fits together and allows for secure processing and delivery of the insights.
Example
Here’s a scenario that highlights both the power of innovation and the challenges of protecting privacy: two hospitals are teaming up to study the long-term effects of a rare disease. The key to their research? Patient data stored in backups, potentially dating back decades but they want to extract the value of all of the data - not just what is currently online in their production systems.
Now, you can imagine the hurdles. These backup sets contain data that is invaluable in terms of the insights they may unlock, but they also contain highly sensitive personal information (PII and PHI). How do you extract meaningful findings while respecting patient confidentiality and compliance?
Technology like Azure Confidential Clean Rooms could provide the perfect environment for this. They create a secure space where backup data can be accessed/provided and analyzed without exposing private information.
Analyzing data from backups isn’t as simple as running queries on a database or application with an API. It’s messy. You’re probably dealing with inconsistent formats, legacy records, and vast amounts of historical information. Researchers need to test patterns, refine machine learning models, and iterate many times before landing on any of the actionable insights these may unlock. All whilst maintaing privacy.
Here’s how we make it could work: first, we bring the backup data into a secure environment, for example via the Veeam Data Integration API or other file-level recovery options. Researchers only receive anonymized outputs and aggregate trends—during their analysis. Meanwhile, a special data repository is configured to handle any patient-level data that might need to be shared for regulatory or clinical purposes.
This setup lets researchers refine their models and validate findings while keeping the raw, sensitive data completely out of reach. Once they’ve verified their results, specific insights—like trends or anonymized outcomes—can be shared. If patient-level data is required for follow-up studies, it’s routed securely to an authorized clinical team, never to the researchers themselves.
Wrapping up
Platforms like Azure Confidential Clean Rooms coupled with invaluable data sets held in backups, surfaced by Veeam can ensure this process runs seamlessly. Anonymized summaries go to the researchers, while sensitive details are securely locked away for authorized use.
As a Field CTO in the data resiliency space I have conversations on a weekly basis of privacy and security, but also the data held in backups. I love how this approach taps into the untapped potential of historical backup data. It enables transformative medical (or any other!) research without compromising the trust or privacy of the individuals whose data is being used. It’s a win-win for innovation and protecting sensitive personal information.