

Chat privately using Ollama on your own infrastructure. Llama2 and Mistral on an NVIDIA A40 48GB GPU

With Large Language Models taking the world by storm in 2023 organisations have had to scramble to put policies in place to prevent employees putting sensitive information into these public platforms.
In response to this, and other factors like cost predictability has meant that a bunch of smart people have been working on how to run models locally which we can leverage inside the bounds of our networks in which we can control.
Today we will looking at Ollama (ollama.ai) which will very quickly let us leverage some local models such as Llama2 and Mistral.
The hardware
- Virtual machine with 64gb memory, 4 cores
- Nvidia A40 with 48gb profile, presented through the VMware
- Ubuntu 23.04, with the correct NVIDIA CUDA drivers installed
Installing Ollama
This is super simple, they have manual install instructions but I just used the one-liner they also provide, as below;
curl https://ollama.ai/install.sh | sh
Let that do it’s thing and then can use your shell to call ollama and pull down models.
Install / pull models
There is a library of models available and you can run as many of these as you need locally. New ones are being added or updated all of the time. Let’s take a look at Mistral.
ollama pull mistral
 Once model has been pulled you can rinse and repeat with other models such as Llama2.
Once model has been pulled you can rinse and repeat with other models such as Llama2.
You are now ready to start using the model locally.
Talking via the command line
Choose a model then issue the run model command
ollama run mistral
You can begin to chat! Ask it to write code, make jokes. This is realtime by the way, pretty good performance!
 So this is handy, by really we want to be able to integrate these into our chatbots or business applications. This is where the API comes in.
So this is handy, by really we want to be able to integrate these into our chatbots or business applications. This is where the API comes in.
Setting up the API
If you are always planning on calling this locally then you can skip this step. Chances are though you will like me, want to publish this externally.
By default the API binds itself to 127.0.0.1 so external access even on the local LAN address will not work. But it’s a simple fix.
On Linux:
Create a systemd drop-in directory and set Environment=OLLAMA_HOST
mkdir -p /etc/systemd/system/ollama.service.d echo '[Service]' >>/etc/systemd/system/ollama.service.d/environment.confecho 'Environment="OLLAMA_HOST=0.0.0.0:11434"' >>/etc/systemd/system/ollama.service.d/environment.conf
Reload systemd and restart Ollama:
systemctl daemon-reload
systemctl restart ollama
Now, you can hit this on the local LAN address and expose this appopriately through any firewall, reverse proxy etc you need.
Working with the API
For this its a pretty simple payload, we can POST to /api/generate with at minimum the model and prompt to get some data back.
{
"model": "mistral",
"prompt": "Tell me 3 dad jokes about christmas."
}
You will note though when calling this manually, we actually by default get the streaming response back as a tonne of json objects. Extract below.
{
"model": "mistral",
"created_at": "2023-12-15T00:47:01.078192237Z",
"response": " Why",
"done": false
}
{
"model": "mistral",
"created_at": "2023-12-15T00:47:01.089194367Z",
"response": " was",
"done": false
}
{
"model": "mistral",
"created_at": "2023-12-15T00:47:01.100180395Z",
"response": " the",
"done": false
}
{
"model": "mistral",
"created_at": "2023-12-15T00:47:01.111236223Z",
"response": " Bel",
"done": false
}
{
"model": "mistral",
"created_at": "2023-12-15T00:47:01.122245433Z",
"response": "ieve",
"done": false
}
This is useful when we want to work with this in code and our chatbots as we can stream the tokens as they come out of the model in real time.
If you just want to use this to get a single generated response you can do this by adding stream: false in the payload
{
"model": "mistral",
"prompt": "Tell me 3 dad jokes about christmas.",
"stream": false
}
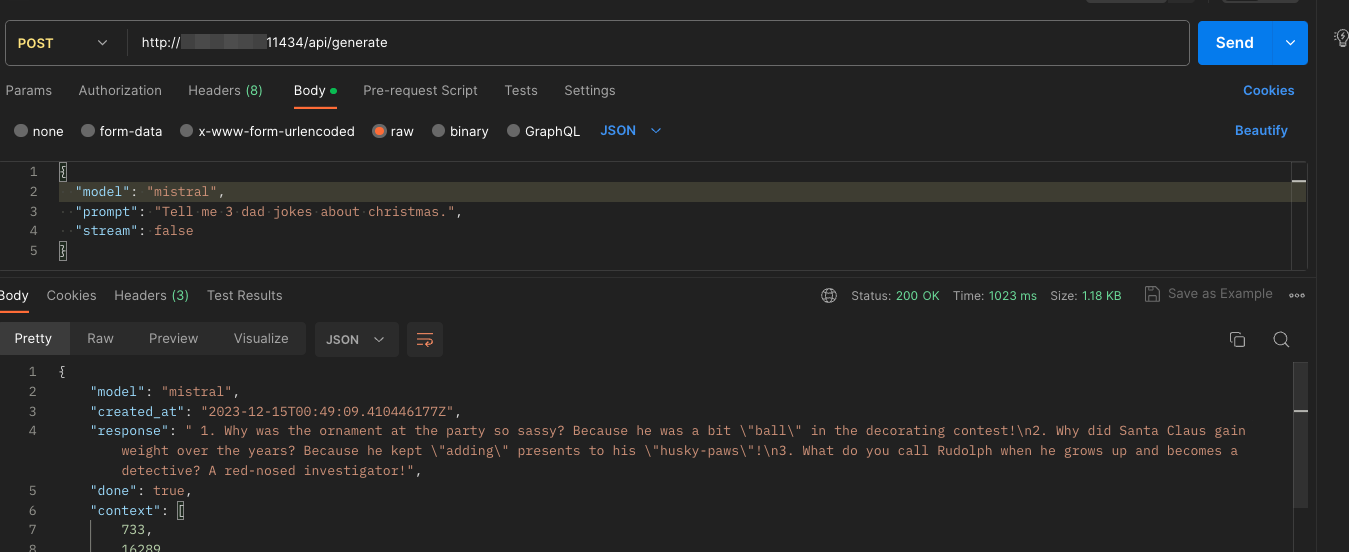 Now the response (takes a little longer) but we get a single response object we can work with.
Now the response (takes a little longer) but we get a single response object we can work with.
{
"model": "mistral",
"created_at": "2023-12-15T00:49:09.410446177Z",
"response": " 1. Why was the ornament at the party so sassy? Because he was a bit \"ball\" in the decorating contest!\n2. Why did Santa Claus gain weight over the years? Because he kept \"adding\" presents to his \"husky-paws\"!\n3. What do you call Rudolph when he grows up and becomes a detective? A red-nosed investigator!",
"done": true
}
Pretty cool eh!
Now you can interchange model: “mistral” for Llama2 or any other model you wish to use from their library.
Conclusion
Easy setup and nice performance. I can’t wait to put together one of my chatbot applications to leverage these and see how they compare to some of the public services such as OpenAI.