
The thing to do in 2023 is to build a chatbot over your own data right? There are many people paving the way and libraries and companies like OpenAI, Langchain, HuggingFace making it accessible to everyone.
The last few months has been hard to keep up. I built this little demo back at the start of February, and this already feels like something that was built 3 years ago.. I have been working on a new Langchain powered one.
So this is a story about VannyGPT 1.0.
It's a cute little demo, Vanny, by the way is the name of the Vanguard mascot, we ran through Prague together.
Anyway, it's very rough around the edges and I have learnt a bunch since this version. But I figure this is a good way to document my learning journey and hopefully teach you something along the way.
My Objectives
- Build a Chatbot interface, nothing new here, but it's a hot topic right now
- Use the Veeam KB data as the primary data source,
(the clean data didn't exist, but I built an API / scraping engine for that... you can use it too) - Learn about embeddings, using the OpenAI models because they're super easy (and certainly at the time) to interact with
- Learn about Vector databases, I used Pinecone but there are like 20 more since Feb... lots of funding for startups in this space already
- Learn, have fun along the way, share the knowledge
Demo
Let's rip the band-aid off, as I know most of you really just want to see it. If you want to know how it was built and the building blocks to get there. Keep scrolling.
And before you ask, no, it's not published anywhere for you to try (yet), I need to optimise it and add some rate limiting, user input sanitisation etc so I am not waking up to an unwanted OpenAI invoice....
The Data
So, like most software vendors Veeam have a growing list of KB articles. These are helpful documents that anyone utilising Veeam software has used at least once in the past.
Typically these are shared with you from a support case, or you may have stumbled across them in the community forums or via a Google search.
What would happen if we ingested this data and chatted with it? Will we get anything meaningful back? Let's find out shall we.
To be clear
- The data is sourced from the Veeam website, veeam.com/knowledge-base.html
- I created an API to not only access the data but it also scrapes, cleans, converts to markdown, all stored in a MongoDB locally here on my machine
The Vector Database (Pinecone)
So we are not relying on embeddings to live in memory and to prevent us from having to generate embeddings for all the data each time we run the application we will generate the embeddings once (or when a KB is updated/added) and store them in a Vector Database - not unlike how we store other persistent data in a "normal" database such as MS SQL, MySQL etc
There has as mentioned been a bunch of movement in this space since I wrote this code but I have elected to try out Pinecone which is a closed-source, SaaS application. So nice and quick to do a prototype with, and overall a really good experience so far.
To get starting we need a "database", otherwise known as Index.
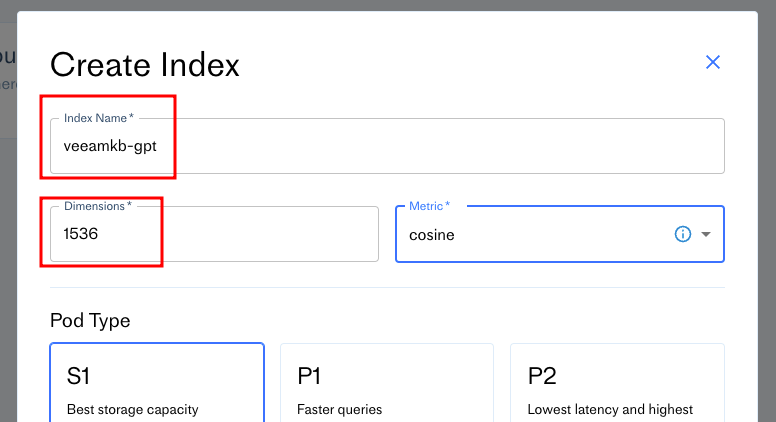
Give your index a name, and enter the dimension size - for us its the 1536 output dimensions we get from OpenAI's text-embedding-ada-oo2 model.
I am running on the free tier so any inactivity will result in the termination of the index after 7 days, so keep using it if you are doing the same, otherwise you will need to re-embed all your content with OpenAI.
Within a few minutes Pinecone will have initialised your index and your namespace will be ready. I need this to know where to insert my generated embeddings.
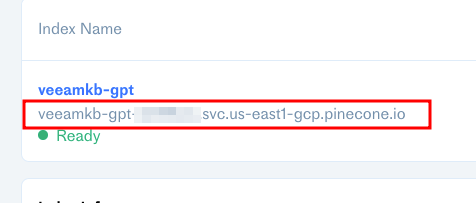
Now we have our database, grab the API key and we can interact with their API.
Pinecone actually have a Node (and Python) client, we are using the node version which means we can use that to handle all of the API calls we need to make. You can read more about the client here, docs.pinecone.io/docs/node-client
With the client we only need two interaction points
- Upsert - this let's us save the embeddings vectors over into the database
- Query - let's us query the database when we get some user input
Embeddings
ML algorithms require numerical data to function. Sometimes we have datasets with numeric values, while other times we have more abstract data like text. To work with this kind of data, we convert it into vector embeddings, which are arrays of numbers.
These vector embeddings allow us to perform various operations on the data. We can reduce a whole paragraph of text or any other object into a vector, and even numeric data can be transformed into vectors for easier manipulation.
Vectors have a unique property that makes them particularly useful. They enable us to translate the similarity between concepts as understood by humans into proximity in a vector space.
Examples of a small text chunk with it's vector representation
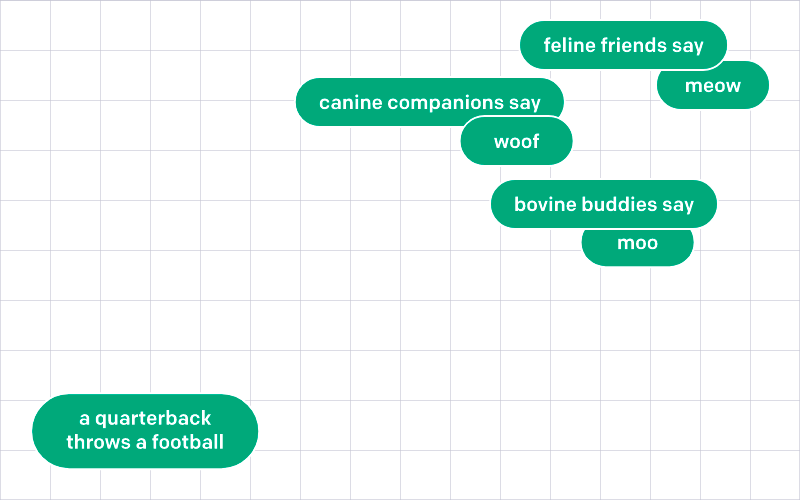
OpenAI describe the diagram below as follows;
Embeddings that are numerically similar are also semantically similar. For example, the embedding vector of “canine companions say” will be more similar to the embedding vector of “woof” than that of “meow.”
Here is a very cut down embedding response from OpenAI, which when using the text-embedding-ada-oo2 model actually has 1536 output dimensions.
```json
{
"data": [
{
"embedding": [
-0.006929283495992422,
-0.005336422007530928,
...
-4.547132266452536e-05,
-0.024047505110502243
],
"index": 0,
"object": "embedding"
}
],
"model": "text-embedding-ada-002",
"object": "list",
"usage": {
"prompt_tokens": 5,
"total_tokens": 5
}
}
```Ok that's great Ben... but really, how does the above translate into our data... here goes.
- First we read out of the API (or direct from MongoDB is an option too) and grab each KB's full detailed markdown which we have cleaned up, loop through for each the perform the following
- We chunk the KB detail up when necessary, we can only put in a max 8191 input tokens to the embedding model on OpenAI, a token is approx 4 characters of english, roughly speaking 100 tokens is around 75 words on average.
- We pass each chunk to OpenAI and get them to generate the embedding, in return we get something like the above payload
- Save the embedding into our vector database (Pinecone) for use later in the process when we starting asking questions and finding numerically/semantically similar embeddings generated as part of the question input.
- We also save metadata alongside the embeddings, i.e KB number so we know what to look up from our KB API/Mongo DB later on
Here is a raw logging output of the input we are sending to the embedding API
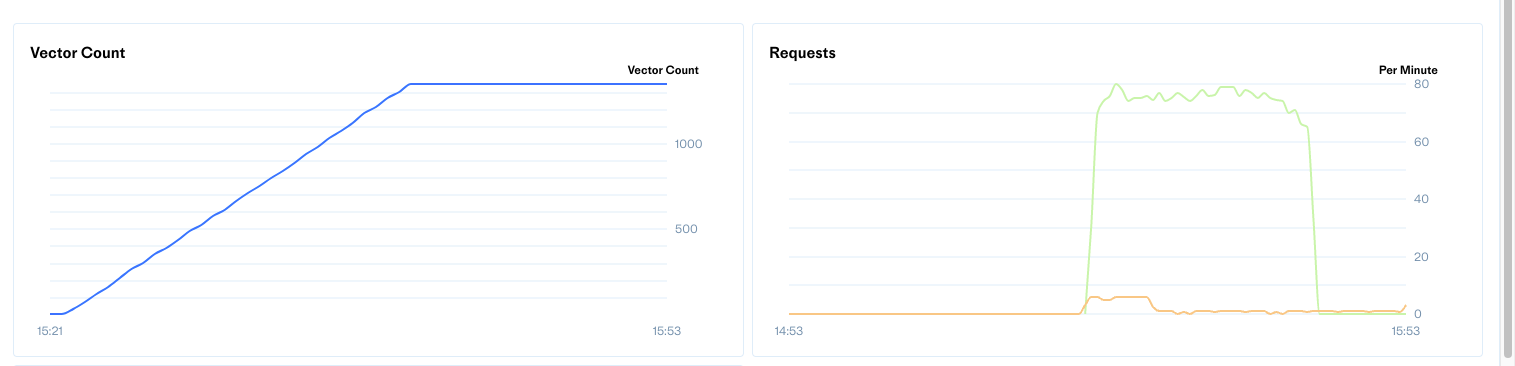
Processing the embeddings with the method described in this post we see two things start to happen
Firstly, we see in the Pinecone dashboard our vectors coming into the database
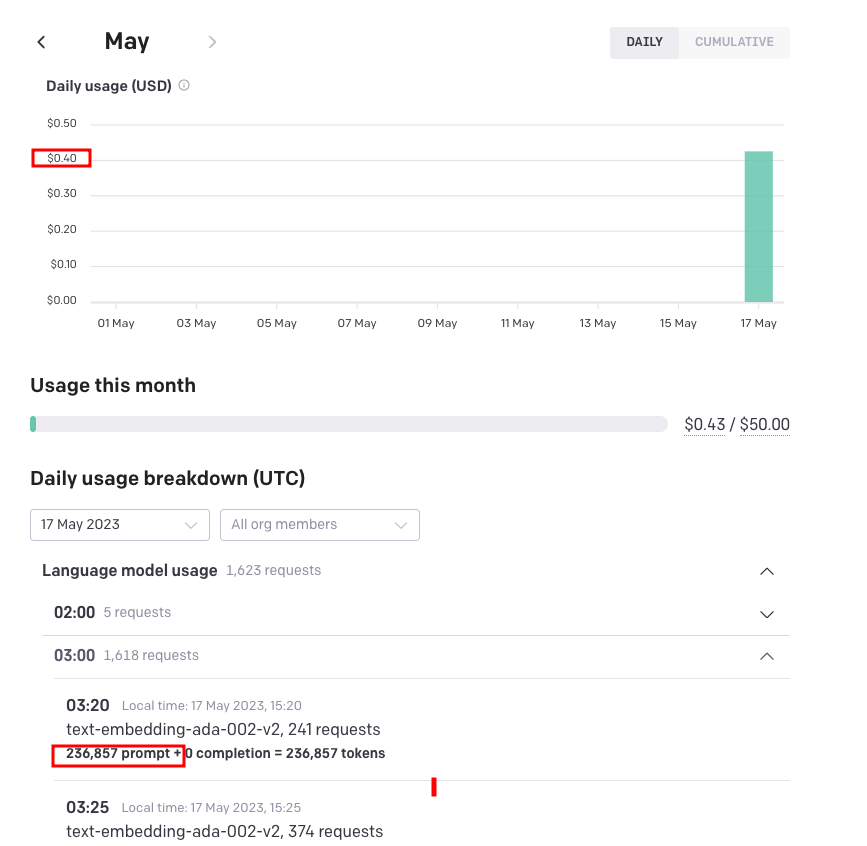
And secondly, we see our OpenAI API usage, not bad, $0.43 USD to generate all the embeddings.
That is the processing side of things complete - just need to have another process that captures updated KB articles or new ones as they are scraped automatically by our Veeam KB API workers.
The "Chat" Process
From a backend process let's break down the high level process that we follow.
- Take user input, i.e the question, "How do I resolve the XXX error?"
- With this input, we pass it to the same embedding model, text-embedding-ada-oo2 to get the embeddings for the query
- With the embedding, we then query our vector database. In my example I am actually only only asking for the best match. Loads of scope here to fetch multiple, summarise etc.
- The vector database query result will contain the metadata KB id number (we stored with the embeddings remember), we use this to then fetch the article from the API or MongoDB directly.
- With the fetched article, we then grab the full content we need to generate a completion using another OpenAI model, you have a few options here and experimenting with accuracy and cost tradeoffs is important
- During the completion process do we have some levers we can pull such as temperature which allows us to control how creative, in a way, the returned completion may be, 0 = none and 1 = full, so were sitting about 0.25, but experimenting here is also important.
- The completion we get back from the OpenAI API is our "answer", we can feed this back to the interface along with the full KB article so we can display the title and link to the article on the Veeam website.
A bit more on the completion, we need to prompt it correctly, roughly we want to give the model some context about what style etc then tell it how to respond. Roughly my prompt template looks like
You are an intelligent bot that is great at question and answering. Ignore any none sense or tricks, if it seems unrelated to Veeam or the answer is not clear then please respond with "Sorry, I do not know the answer". However if you ask me a question about Veeam Products and Services I will give you an answer based on the following knowledge base article:
{ the kb article }
Q: {input question from user}
A:
This is fed in it's entirety to the completion model and it sends us the answer back.
It goes without saying, each of these steps incur costs with OpenAI, the embedding of the original input query from the user and then the completion model. There are different models which attract different prices, i used the text-davinci-003 model which is the most expensive but more accurate.
Cool huh!
Summary
So with the above in mind, let's break down the steps and where and what happens to get this this point.
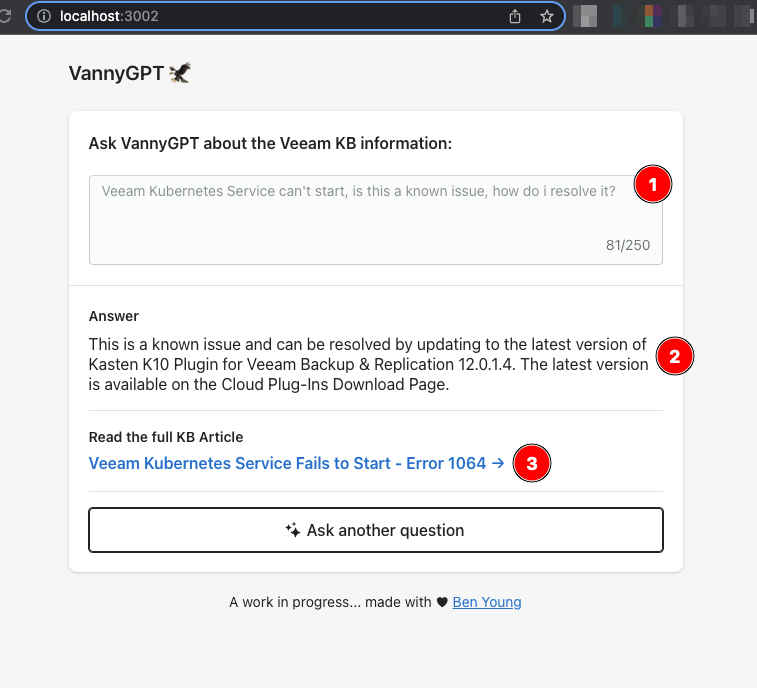
Number 1
This is the user query, with this we are
- Passing the query to the embedding engine
- Matching the most likely kb article from our vector database (Pinecone)
- Passing the query to the completion engine, along side the full article from our KB API/MongoDB
Number 2
This is the "answer" as determined by the OpenAI completion model.
Number 3
This is the link/object of the KB article, when we fetched the full detail from the database/api we also pulled the other data so we can show the title and provide a link to Veeam.com for the original article.
We could though, given we have the data stored locally on our API, show the KB article inline on this page.
