
When GPT4-V was release everyone was amazed at it's capabilities of being able to interperet visual information such as photographs. A team have put together a multimodal model called LLaVA (Large Language and Vision Assistant) which is free to use.
I wanted to give it a go through my Ollama private instance running on a virtual machine in the datacenter with a 48gb NVIDIA GPU.
I first updated my Ollama instance to the latest 0.1.16 build which has support for this now. Then pulled the model down.
ollama pull llava:13b
Thats the housekeeping out of the way, only thing left to do now is to try it out via the API.
You need to convert the images to base64 encoding when passing it through but a reduced example below, similar to text only models with the addition of the images array.
{
"model": "llava:13b",
"prompt":"What is in this picture?",
"stream": false,
"images": ["/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAYEBQYFBAYGBQYHBwYIChAKCgkJChQODwwQFxQYGBcUFhYaHSUfGhsjHBYWICwgIyYnKSopGR8tMC0oMCUoKSj/2wBDAQcHBwoIChMKChMoGhYaKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCj/wgARC..."]
}Samples

Prompt: What is in this picture?
Response: In this picture, there is a person holding up a giant slice of pizza. The scene takes place in front of a truck, making it an interesting and unconventional setting for such a large piece of food.
Prompt: Is there a vehicle in this image?
Response: Yes, there is a vehicle in the image, specifically a truck.
Prompt: What footwear is being worn?
Response: The person is wearing boots
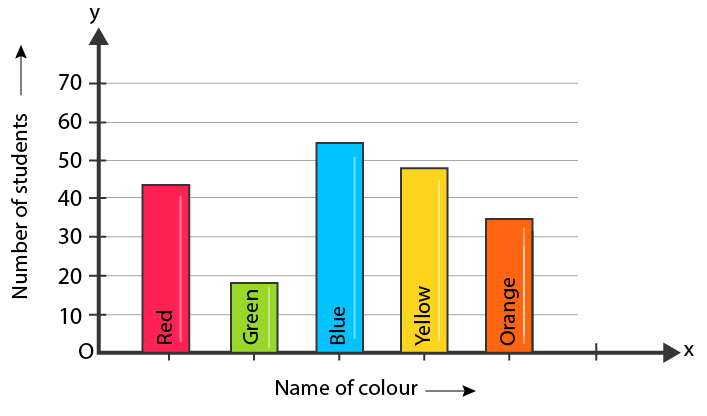
Prompt: Describe this picture
Response: The image shows a colorful bar graph representing the number of students in different colors. Each color stands for a specific number of students, with orange indicating 75 students, green representing 100 students, blue showing 125 students, and yellow symbolizing 150 students. The heights of these bars correspond to the respective number of students they represent.\nThe bar graph is organized in such a way that each color has a distinct line, making it easy to identify the different colors and their corresponding values. This visual representation helps demonstrate the distribution of student numbers throughout the various levels or categories.
Prompt: Give me a concise list of the colors in this image
Response: 1. Red 2. Green 3. Blue 4. Yellow 5. Orange 6. Pink 7. White
Prompt: Does the blue bar have a bigger value than the green bar?
Response: Yes, the blue bar has a bigger value than the green bar.
Prompt: Does the green bar have a bigger value than the blue bar?
Response: No, the green bar has a smaller value than the blue bar.

Prompt: Describe this photo
Response: The image features a beautiful mountain range with snow-covered peaks in the distance. The mountains are tall and majestic, surrounded by trees that add to the natural scenery. There is also a valley visible between two prominent peaks, showcasing the breathtaking landscape. The scene captures the essence of nature and its rugged beauty, making it an appealing sight for any outdoor enthusiast or traveler.
Prompt: How many peaks are visible?
Response: 3 peaks are visible in the image.
Prompt: What species of trees are visible in the image
Response: The image shows a mountain covered with conifers, which are evergreen trees.

Prompt: Describe this picture
Response: The image features a thank you note written on a white piece of paper. The lettering is blue, and the message reads "Thank You!" A pen with gold accents sits on top of the note, indicating that it was recently written. There is also an envelope placed nearby, likely for sending the note to someone
Prompt: Does this contain the name of a person?
Response: No, this message does not contain the name of a person. Instead, it contains the word "thankyou" written on the card by the pen.
Prompt: What language are the words written in?
Response: English
Prompt: What words are hand written on the letter, can you translate them to french?
Response: Merci !
