I have been building out a new API. To cut a long story short I needed a data set for some other projects I have on the go and the Veeam KB data seemed a perfect fit, plus I wanted to enhance it (these are the sprinkles) with referenced Veeam R&D forum posts.
Goals
- Automatically fetch new KB's that are listed and update ones which have had updates provided to them
- Content scraped must be clean, returned as Markdown through the API
- Retain as many of the sections as we can (Problem, Solution etc) as well as provide a full version
- Detect products and versions referenced so we can list applicable products and provide search function in the future
- Find any references in the Veeam R&D Forums, store this information and reference against any of the KB(s) that are linked so you can see any discussion along side the KB
- List API endpoint that can returns KB Articles, paginated, light weight
- Detailed endpoint showing the detailed KB information, any sections plus the full version as well as the enhanced data from the products and related content (Veeam R&D forums) discussion
At first I thought, should be simple enough but as I got into it a few challenges presented itself.
Challenges
There is no API to fetch the KB detail
But there is one to get the list of KB numbers with a small amount of data - this is good as i don't need to slam the Veeam web server to find out if a new KB exists by guessing the number, these usually increment in 1's but not always. Regardless, this is more efficient for us.
The HTML is pretty bloated
When scraping the data for each KB article, the body content of the KB detail itself is fairly typical of a big CMS.
There are loads of nested divs, style classes etc. I really want clean content to work with but still maintain the sections (like Problem, Solution etc). Stretch goal was to also have this in clean markdown format so this needed a bunch of work.
A bunch of other elements are baked through there which were unnecessary so I ended up having a blacklist of elements/class combos that were removed from the DOM before conversion.
The content contains inline forms
Baked in and around the main body are a few forms we need to detect and get rid of from the DOM before converting, one is typically a notify me form and the other being a feedback for mistakes in the content.
Markdown conversion
After cleaning the HTML, conversion to markdown mostly worked but there was a couple of items that needed manipulating before parsing the HTML > Markdown.
- Images are referenced as <picture> elements which contains multiple image sources optimised for different screen resolutions or formats. This does not play nicely with conversion. So I loaded the HTML and manipulated it by detecting these, removing the element from the DOM, finding the biggest image source and then inserting a new image into the DOM in it's place with the reference of the biggest image
- Often the nested div structure wrecked havoc with the conversion so a few regex replacements of tabs/new lines in some conditions were required to clean it up and the markdown to work correctly
Result
Well you can be the judge of it but I am happy and all of the items I wanted for this first version.
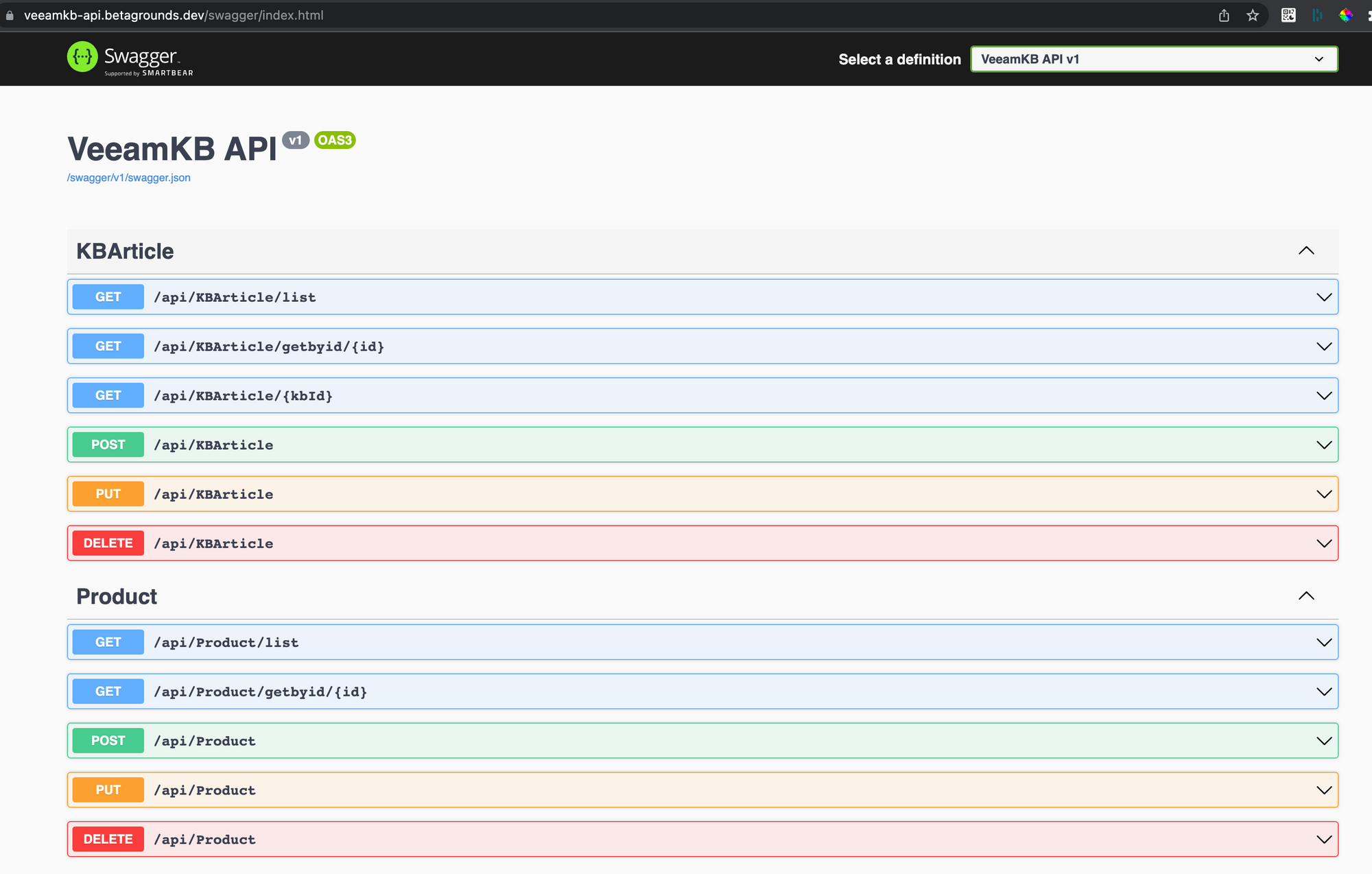
You can find the Swagger reference here and try it out
https://veeamkb-api.betagrounds.dev/swagger
Examples
GET to https://veeamkb-api.betagrounds.dev/api/KBArticle/list
Will return an array (including some pagination data) with the following data objects
{
"id": "64634cd8a52f5b7bf625f11c",
"kbId": "kb4442",
"title": "SharePoint backup jobs fail with: The remote server returned an error: (429)",
"productsReferencedCount": 1,
"relatedContentCount": 2
}
At a glance you can see the title, as well as the count of products referenced, and related content. Let's take a look at the detailed now.
GET to https://veeamkb-api.betagrounds.dev/api/KBArticle/kb4442
We get the following verbose output
{
"id": "64634cd8a52f5b7bf625f11c",
"kbId": "kb4442",
"title": "SharePoint backup jobs fail with: The remote server returned an error: (429)",
"productsReferenced": [
{
"id": "64634cd2a52f5b7bf625f0ac",
"name": null,
"version": 218,
"versionName": "Veeam Backup for Microsoft 365 7.0"
}
],
"relatedContent": [
{
"id": "64634cd4a52f5b7bf625f111",
"sourceUrl": "https://forums.veeam.com/veeam-backup-for-microsoft-365-f47/vb365-the-remote-server-returned-an-error-429-t85555.html",
"title": "VB365: The remote server returned an error: (429) - R&D Forums",
"description": "@Polina would you be able to share some details about what the issue were and how it was fixed? I've seen a pattern in the logs (ProgramData\\Veeam\\Backup365\\Logs\\) which looks like that vb365 on V6, doesn't adhere back off requests (Retry-After HTTP Header), and seem to implement own desired cool down when experiencing an 427 and 503 but nothing shown in the task log which is found quite odd ...",
"scope": "forum",
"lastUpdated": "2023-05-13T06:51:00+12:00"
},
{
"id": "64634cd4a52f5b7bf625f112",
"sourceUrl": "https://forums.veeam.com/veeam-backup-for-microsoft-365-f47/backup-with-errors-t86710.html",
"title": "Backup With Errors - R&D Forums",
"description": "Backup With Errors. So the Microsoft/Office 365 backup has been running for over 14 hours and its showing a bunch of errors. I know its a case by case issue and I know that it depends on the amount of data but for it to take this many hours seems kind of outrageous. There are only three licensed users in this organization.",
"scope": "forum",
"lastUpdated": "2023-05-03T18:49:00+12:00"
}
],
"type": null,
"url": "/kb4442",
"date": "2023-04-08T00:00:00+12:00",
"description": null,
"detailChallengeMdx": "After upgrading to Veeam Backup *for Microsoft 365* 7, backup jobs that protect SharePoint Online objects (Websites, OneDrive, Personal Sites, Microsoft Teams) are interrupted with the following error:\r\n\r\n```\r\nThe remote server returned an error: (429)\r\n```",
"detailCauseMdx": "In some cases, the default Veeam Backup *for Microsoft 365* 7 retry timeout may prove insufficient, leading to an excessive number of requests that could trigger higher throttling. Should this happen, the SharePoint Online throttling policy might hinder the requests sent by Veeam Backup *for Microsoft 365* during the backup.",
"detailSolutionMdx": "The issue is addressed in [Veeam Backup *for Microsoft 365* 7 P20230421 *(7.0.0.3007)*](https://www.veeam.com/kb4425?ad=in-text-link).",
"detailMoreInformationMdx": null,
"detailReleaseInformationMdx": null,
"detailDownloadInformationMdx": null,
"detailManualUpdatingMdx": null,
"detailRequirementsMdx": null,
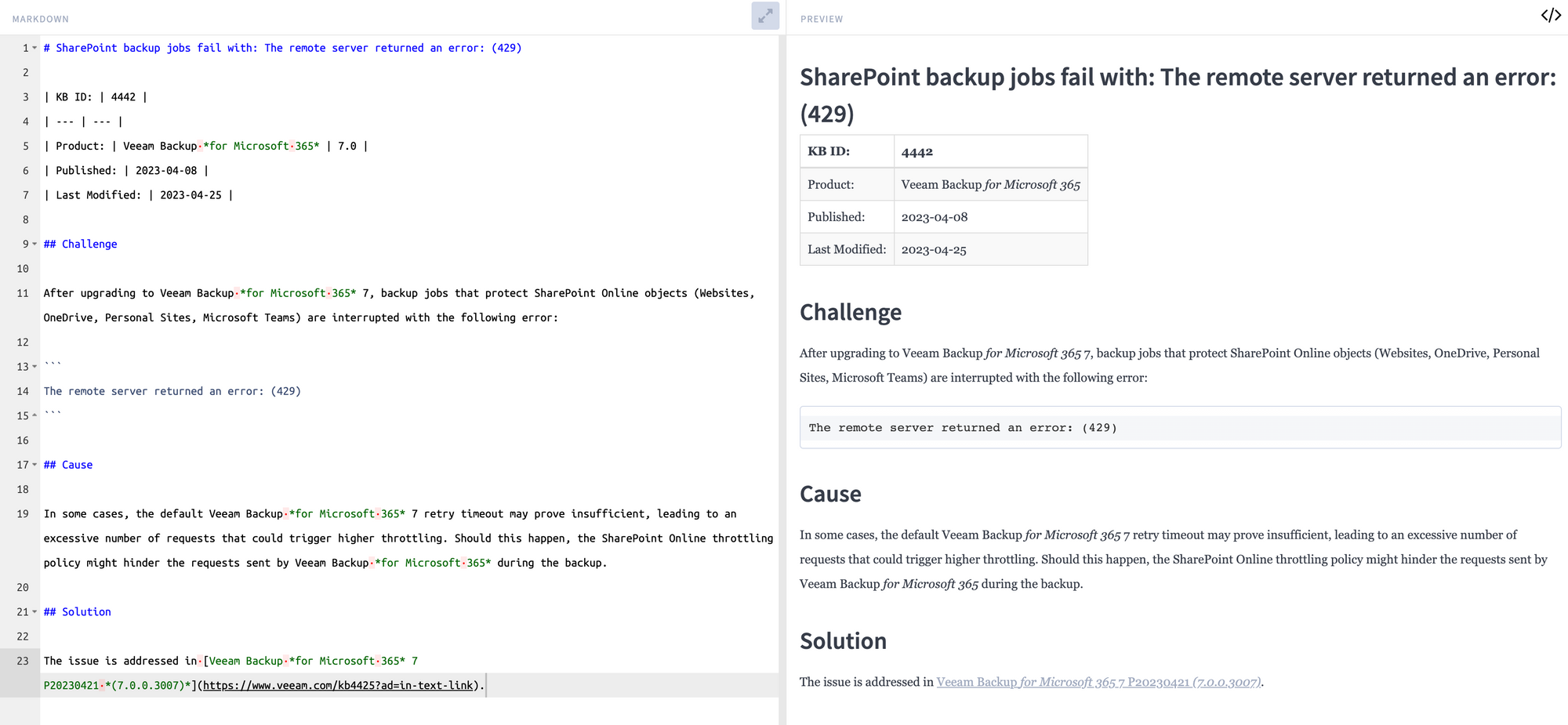
"detailFullMdx": "# SharePoint backup jobs fail with: The remote server returned an error: (429)\n\r\n| KB ID: | 4442 |\r\n| --- | --- |\r\n| Product: | Veeam Backup *for Microsoft 365* | 7.0 |\r\n| Published: | 2023-04-08 |\r\n| Last Modified: | 2023-04-25 |\r\n\r\n## Challenge\n\r\nAfter upgrading to Veeam Backup *for Microsoft 365* 7, backup jobs that protect SharePoint Online objects (Websites, OneDrive, Personal Sites, Microsoft Teams) are interrupted with the following error:\r\n\r\n```\r\nThe remote server returned an error: (429)\r\n```\r\n\r\n## Cause\n\r\nIn some cases, the default Veeam Backup *for Microsoft 365* 7 retry timeout may prove insufficient, leading to an excessive number of requests that could trigger higher throttling. Should this happen, the SharePoint Online throttling policy might hinder the requests sent by Veeam Backup *for Microsoft 365* during the backup.\n\r\n## Solution\n\r\nThe issue is addressed in [Veeam Backup *for Microsoft 365* 7 P20230421 *(7.0.0.3007)*](https://www.veeam.com/kb4425?ad=in-text-link)."
}
Some points of note other than the obvious
- The related content shows links to the R&D forums, plus a little intro description
- The products array is the related product name/version combo found
- The detail.....Mdx sections are where we are trying to detect the different sections, where null, this is where that doesnt existing for that KB - the format varies a lot. The one above has Challenge and Solution
- You can get the full Markdown response int he detailFullMdx which can be rendered for example as below
That about sums it up, there are a few other endpoints available which will be obvious if you hit them.
For now, you can ignore the create/update endpoints, these are behind some auth.
ICYMI: You can get to the Swagger interface here..
https://veeamkb-api.betagrounds.dev/swagger
Future enhancements
- Twitter Bot, automatically post new or updated KB's to Twitter
- Create a new concept UI to consume this API
- Allow users to register a web hook endpoint so we can push new or updated KB's to them (i.e Teams, Slack etc)
- Write a command line cli tool so you could type "veeam-kb 4414" and have it return markdown rendered in your terminal, example below;