
Instant Recovery is one of those technologies that Veeam keeps iterating on and it still blows my mind how capable, powerful and relevant this technology is today.
I have blogged about some of the various different applications of Veeam Instant Recovery technology and this post is a continuation of that.
Let's set the scene here
Note these are just my lab settings, you can tweak the capacity tiering as meets your own requirements
- In my lab I have it protected with Veeam Backup and Replication
- My backup repositories are part of a scale out backup repository (sobr)
- This sobr has one performance (on premise) extent where the jobs land first
- This sobr tiers out using the capacity tier functionality to object storage when backups are older than 2 days
- The capacity tier is also immutable which protects us from ransomware, operator error etc etc meaning the backups on the capacity tier can't be changed/removed until this time is up, pretty powerful - I have set 10 days.
- To give me some additional options / data to play with I also do an immediate copy of all backups hitting the performance tier rather than waiting for it to each the 2 day old mark
What this looks like, see my SOBR2-Dev backup repository.
- EXT2-Local is the performance tier
- mycloudspace-dev is a lab cloudian environment I have access too (located off-site to my lab)

For this test I am keeping it simple. I have a backup job targetting a small windows File server (the one i have used in the past for my Data Integration API demos). This targets the SOBR2-Dev sobr.
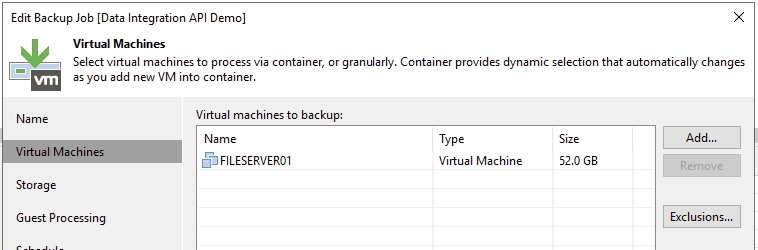
I also have a GFS policy set for testing out some other functions once this job has enough runs under it's belt. Buy you can see the target repository selected.
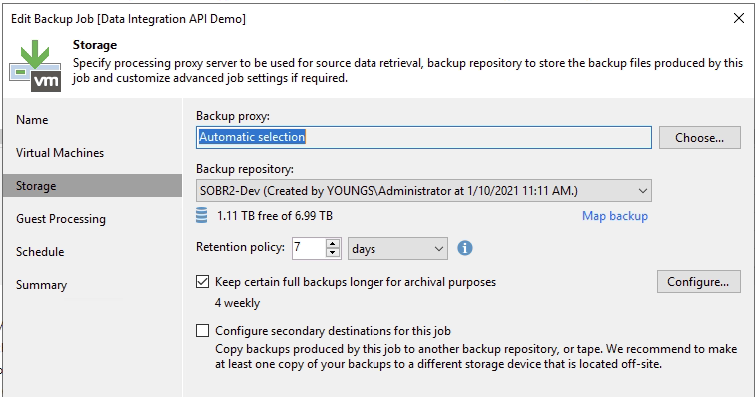
The rest it pretty standard daily scheduling etc.
On the ransomware / immutability front, here is a view of the capacity tier that makes up SOBR2-Dev, note the immutable flag for 10 days, as Veeam writes data in there it tells the object storage that these blocks can't be removed until this time.
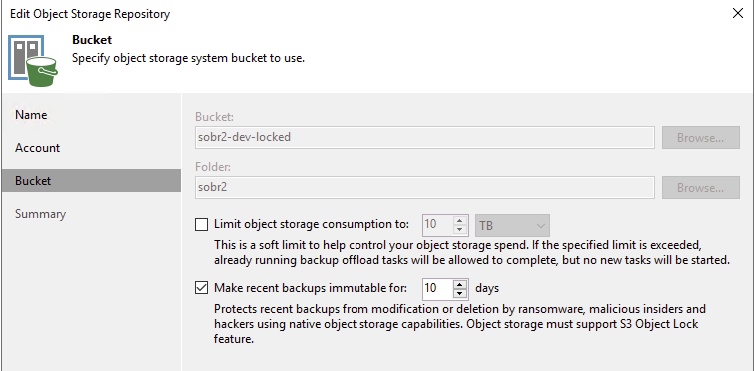
Now as the job has run Veeam begins making sure it meets our requirements around copying data to capacity immediately, moving backups off performance older than a couple of days so we don't run out of performance storage. Remembering that our "capacity" is on object, that is also immutable.
That's the scene setting done. The jobs have run, let's blow some minds.
Recovery Scenario
Right - bad day in the office - we have lost the backup environment and our on premise hosting is compromised.
We have those immediate backup copies going to object storage which is off-site, let's recover from them.
For this test I am going to show you how powerful and portable Veeam really is. The backup server I am restoring on to as well as the compute cluster is not part of my environment.
First thing is we need to add our object storage repository, hit up Backup Infrastructure in the console.
Add a repository with a type Object storage
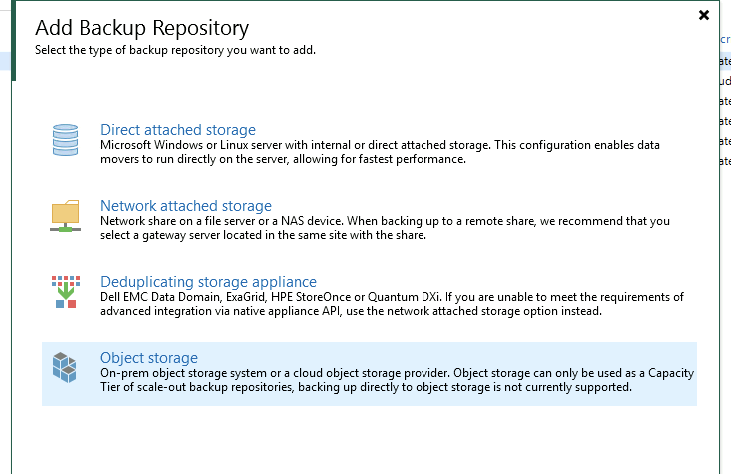
My one is a Cloudian array, so i am selecting s3 Compatible, you can select the other pre-configured providers such as AWS, GCP, Azure etc if this is where your data is landing.

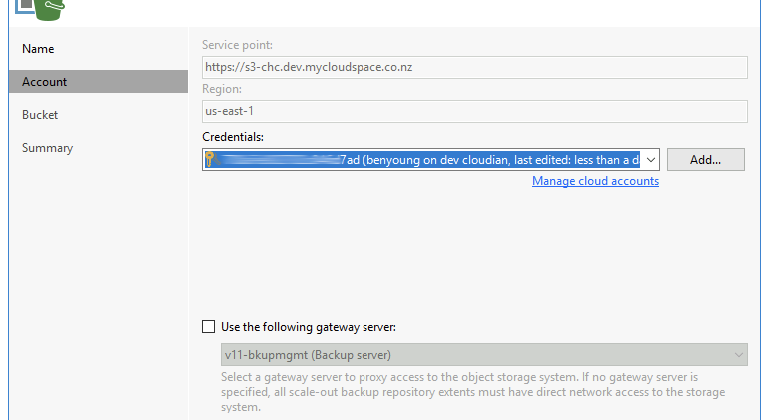
Give your repository a name, then move to the account selection, enter in your service endpoint such as s3.yourprovider.com and regional details.
At this point you will also need your credentials (access keys) to attach to the object storage so hopefully in this scenario you had them available for scenarios like this.... you can add them from this interface just click the add button. Should look something like this;
Now select the bucket and folder corresponding to your capacity tier
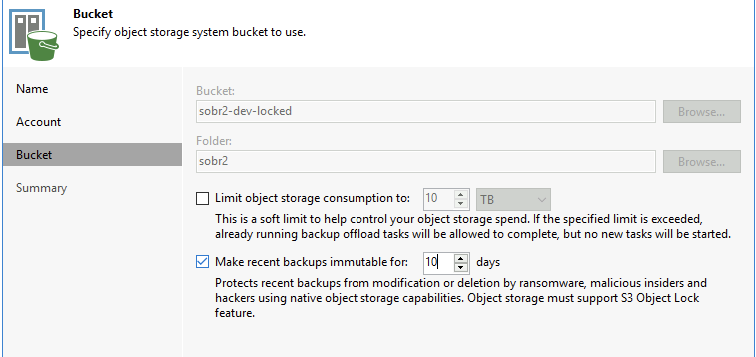
If you were using the immutable object lock functionality you will need to select the box here and enter a value, otherwise you will get an alert/error saying it can't remove the object lock flag.
Now continue to the end of the wizard.
Time to scan the repository so Veeam can take a peek and work. out what is in there. Under backup infrastructure right click your new object repository and select "Import Backups"
And then confirm with the yes button on the next popup.

Another window will pop up and show you your progress, move through the wizard
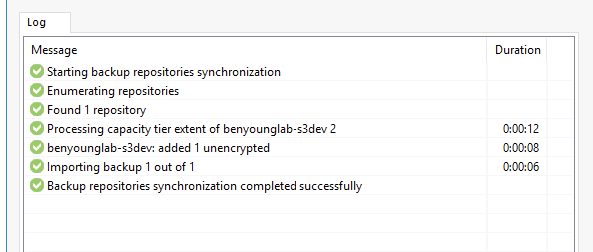
As you can see it did not take long.
Head back home on the console and look under "backups" then Object Storage (imported) you will now see your backup job from the on-premise infrastructure. In my case Data Integration API Demo. Expand it and I can then see any VM's in the job, just FILESERVER01 for me.
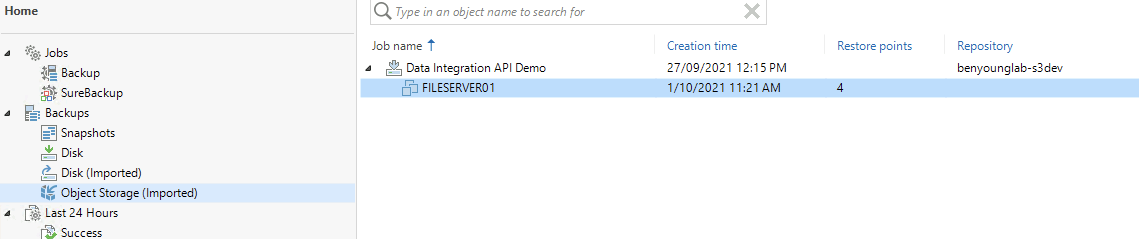
Time to play! right click the VM and you will now notice the VM currently scattered about the object storage repository is a first class citizen of Veeam and you have all the functions to play with.
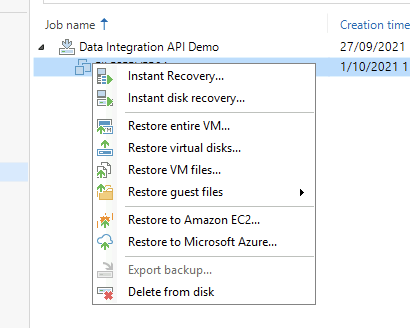
We are here to see Instant Recovery so let's run with that. Take a minute to think what is about to happen here.
- Backup server is going to stream tiny blocks out of object
- Backup server is going to mount a nfs data store to the compute cluster which behind the scenes is actually an object store
- Backup sever is going to create the VM and register it on this virtual centre and use this object-nfs magic to present the storage in real time to the VM, we are going to redirect the writes to a local vmfs present in the cluster
Let's go. Instant Recovery (note you could use my favourite Instant Disk recovery too if you just needed some data...)
Select the restore point.
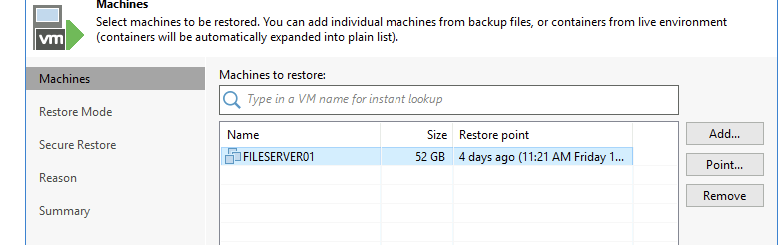
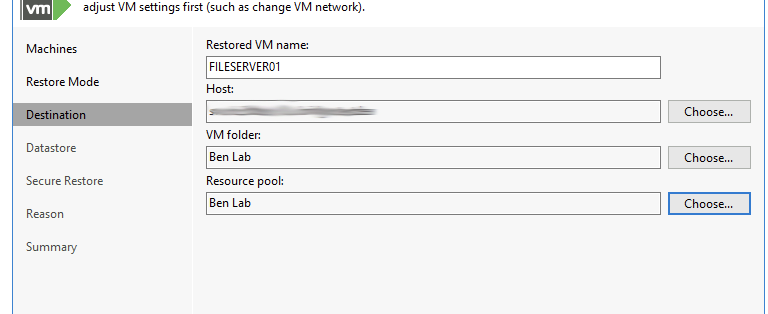
Restore to new location, new settings.

Select some compute destinations/folders/resource pools etc
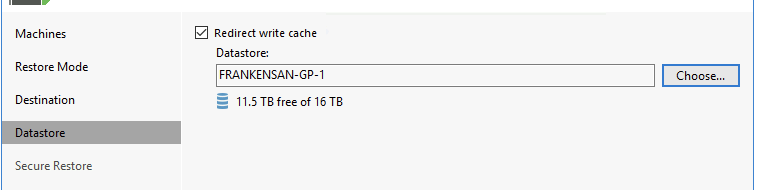
Redirect the write cache to a local VMFS
At this point you could elect to secure restore (malware scan) - but not today for this test.
Next, next... apply. Now watch it work.
VM get's registered, powered on after no time at all.
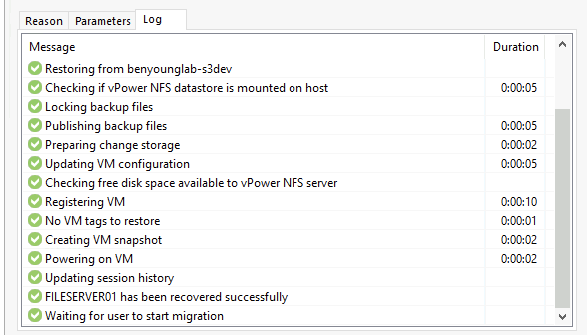
What is that like 30-odd seconds?
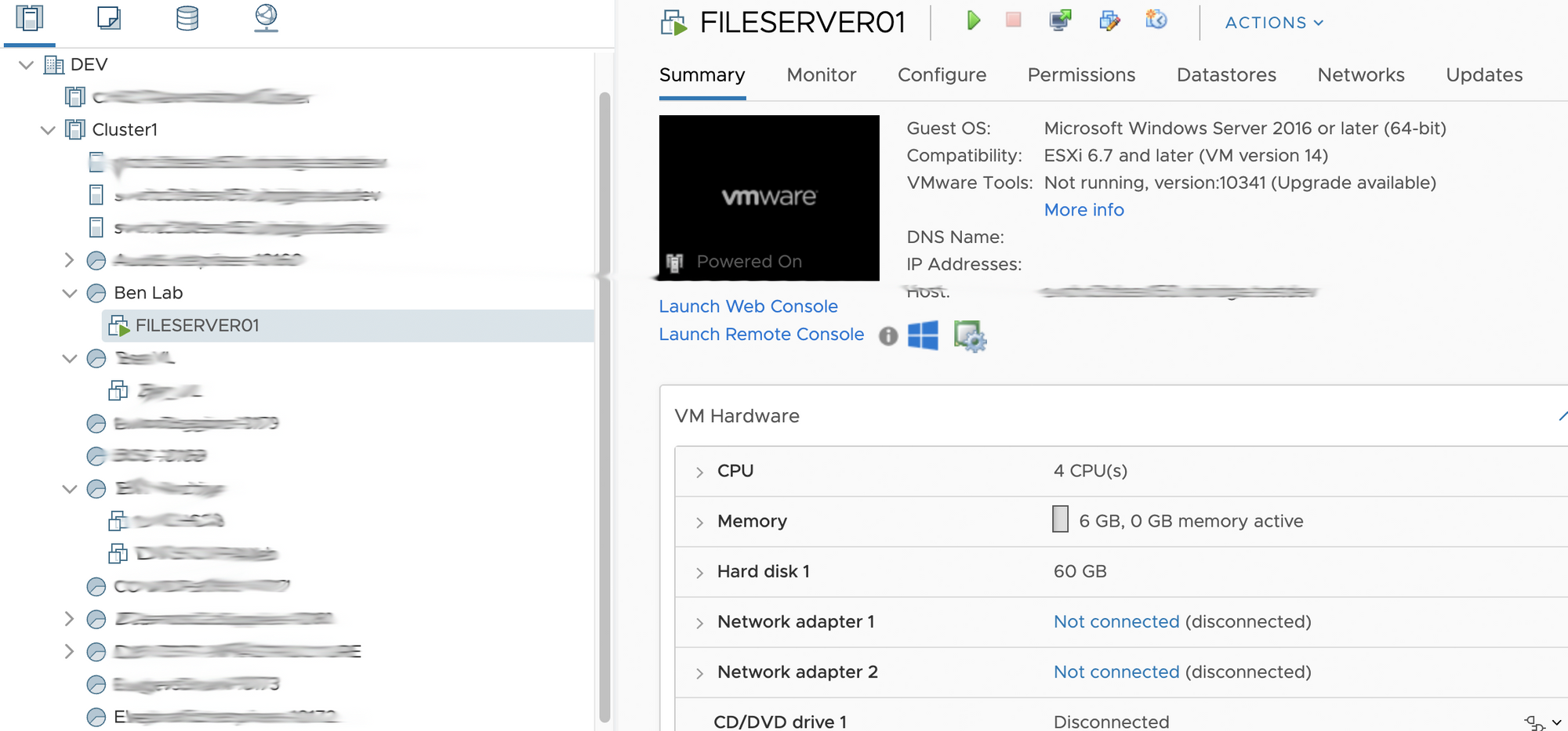
As the machine powers up we can then login via the console or RDP etc if you have all the networking in place.
Performance is actually not bad all things considered and you can see the files are all in tact, below is the files I use for the data integration api demo/malware scanning or object detection.
VM console view
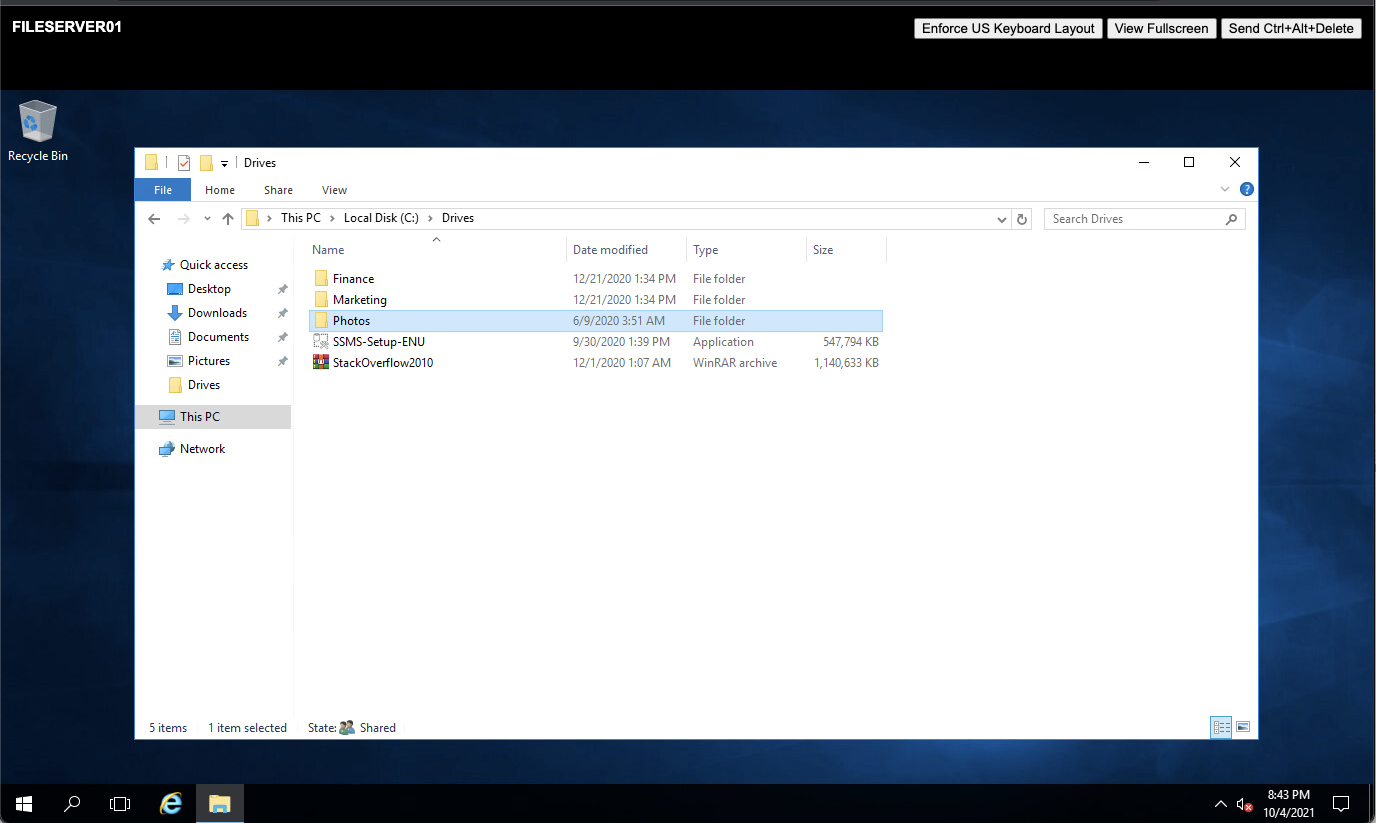
If we extract that 1gb zip let's see what happens.
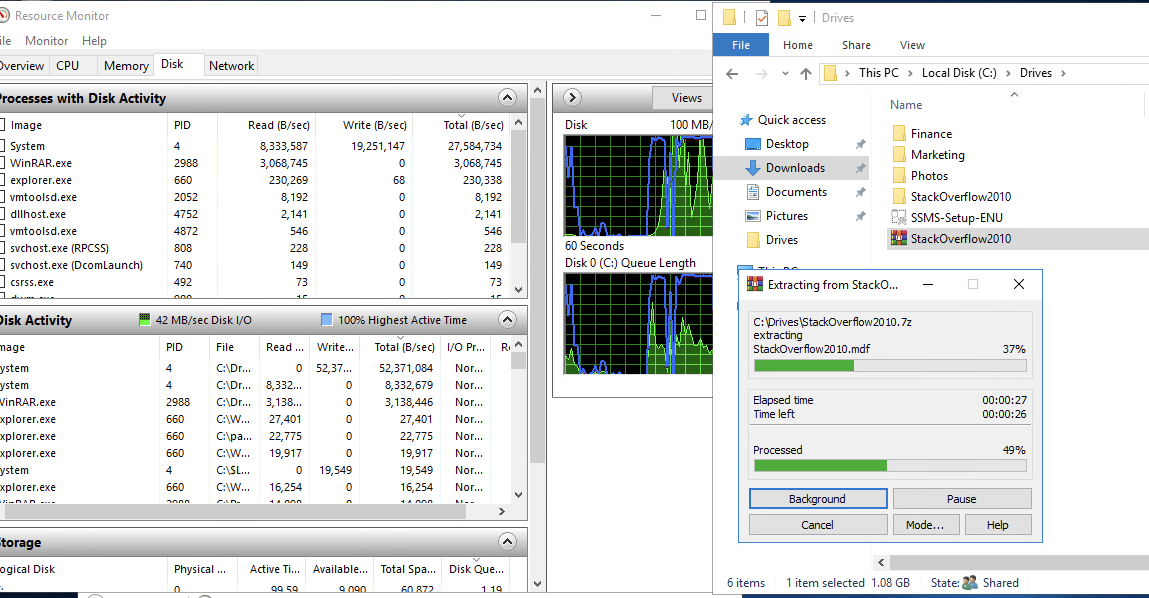
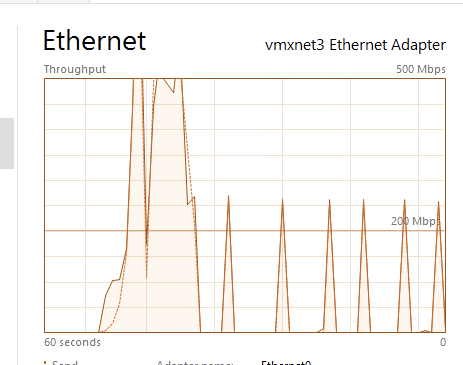
On the backup server that is connected to the object storage you can see even with this little dev cloudian 3-node environment performance is still pretty good. Peaking around 500mpbs during that extraction.
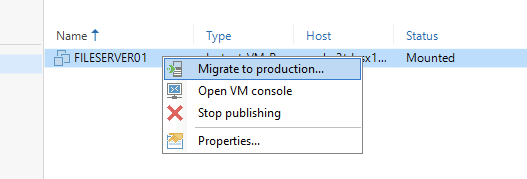
What's more, now we are running we can perform a LIVE migration to production, effectively a storage vmotion from object... to.... block.
I don't know about you but.

#mindblown
